- Как Google обрабатывает PDF?
- Правильное использование PDF-файлов
- Опция 1: Убедитесь, что PDF-файлы, которые не являются целевыми страницами, не проиндексированы
- Вариант 2: Определите индексируемость PDF-файлов, которые имеют отношение к индексации
- Заключение
Документы PDF предлагают большое преимущество перед документами других типов: они выглядят одинаково на любом устройстве.
После создания файла PDF каждый элемент (заголовок, изображение, текст) остается в одном и том же положении независимо от используемого формата PDF. Эта статья покажет вам, как оптимально использовать PDF-файлы для вашей стратегии SEO.

Как Google обрабатывает PDF?
Для высококонкурентных ключевых слов PDF-файлы редко появляются в топ-10 результатов поиска. Однако технически Google не делает различий между страницей HTML и документом PDF. Поисковая система фокусируется только на предоставлении пользователю лучших результатов поиска.
Тексты: Google может индексировать PDF-файлы на любом языке или кодировке символов, если документ не защищен паролем и не зашифрован. Тексты, которые реализованы в виде изображений, частично обрабатываются и «читаются» с использованием алгоритмов OCR. Вы можете узнать, может ли Google читать ваш PDF-текст без затруднений, с помощью простого теста: если вы можете копировать и вставлять текст из PDF-файла, у Google не будет проблем с чтением и пониманием текста.
Изображения: изображения в файлах PDF не очень подходят для классического Google поиск изображений , Если вы хотите, чтобы пользователи находили вас с помощью изображений в файле PDF, вам следует использовать классическую страницу HTML.
Ссылки: Подобно HTML-документам, PDF-файлы также могут содержать ссылки, которые могут наследовать сила связи , Это было недавно подтвердил Гари Иллис:
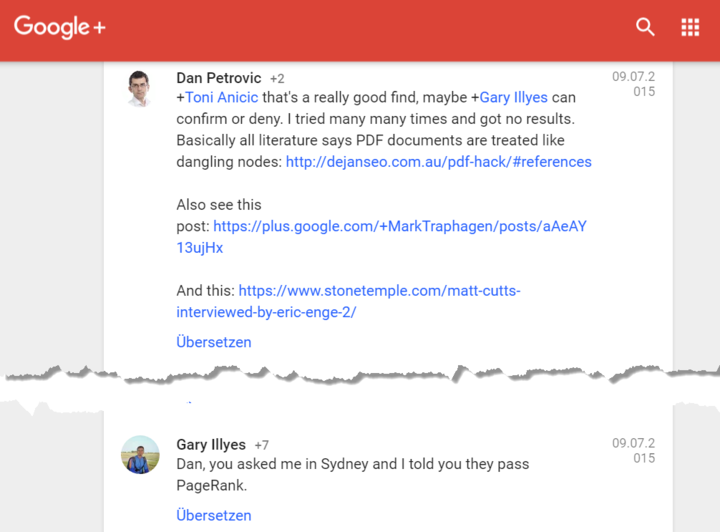
Рисунок 1: Ссылки в PDF передают мощность ссылок
Примечание. При использовании файлов PDF всегда имейте в виду, что посещения PDF не регистрируются такими инструментами отслеживания, как Google Analytics. Поэтому ваш PDF может иметь много посетителей, но этот трафик не используется соответственно.
Чтобы определить потенциальные и слабые стороны, рекомендуется выполнить анализ файла журнала, чтобы оценить посещения файлов, отличных от HTML. Анализ файла журнала также хорошо подходит для оценки действий сканера на основе пользовательского агента.
Правильное использование PDF-файлов
С точки зрения поисковой системы, PDF-файлы - тема обоюдоострая. С одной стороны, PDF-файлы могут быть перечислены в результатах поиска, как и другие типы документов. С другой стороны, они не предлагают пользователю никаких элементов навигации или взаимодействия.
Поэтому важно определить фактическую роль, которую играют PDF-файлы в вашей стратегии SEO. Самый важный вопрос, который нужно задать себе: «Может ли PDF соответствовать ожиданиям посетителя поисковой системы?»
Опция 1:
Убедитесь, что PDF-файлы, которые не являются целевыми страницами, не проиндексированы
Если индексируемый PDF-файл не может полностью удовлетворить информационное требование пользователя, вам следует убедиться, что PDF-файл не проиндексирован поисковыми системами.
Самый простой способ исключить PDF-файлы из индекса - использовать x-robot в заголовке HTTP. Это может быть либо с NOINDEX или канонический тег , В то время как noindex только указывает поисковой системе не индексировать содержимое, канонический тег можно использовать для ссылки на HTML-версию PDF.
Вариант использования: что подходит мне больше всего?
Используя noindex в заголовке HTTP для этих PDF-файлов, вы потеряете ценную мощность ссылок, и только те URL-адреса, которые связаны с PDF-документами, выиграют от этого. Использование канонического тега гораздо более практично, особенно для PDF-файлов, которые ранее генерировали много обратных ссылок. Канонический тег передает всю мощность ссылки на соответствующую целевую страницу. PDF не будет отображаться в индексе поисковой системы, а соответствующая целевая страница будет отображаться в результатах поиска.
Рисунок 2: Пример целевой страницы вместо PDF
Этикет:
- Блокировка PDF-файлов в robots.txt file - PDF-файлы все еще будут проиндексированы, а мощность входящей ссылки будет потеряна.
- PDF-версия страницы - некоторые CMS автоматически предоставляют PDF-версию всех HTML-страниц. Использование канонического тега решило бы проблему индексации в этом случае, но поисковым системам все равно придется сканировать PDF-файлы, что приводит к напрасной трате ценных ресурсов для сканирования.
Определить индексируемые PDF-файлы
Вы можете легко и быстро идентифицировать индексируемые PDF-файлы с помощью OnPage.org Zoom. Просто перейдите в «Индексируемость» → «Что индексируемо?», Активируйте «Индексируемый» фильтр (1), а затем нажмите на «Mime-тип PDF» (2).
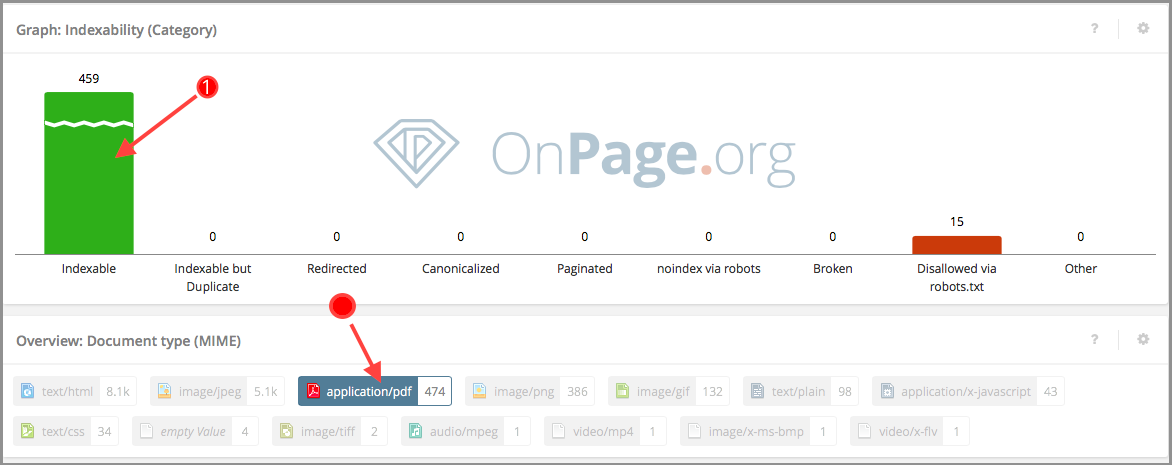
Рисунок 3: Отображение только индексируемых PDF-файлов
После того как вы активировали фильтры, все PDF-файлы, найденные при сканировании, перечислены в таблице ниже.
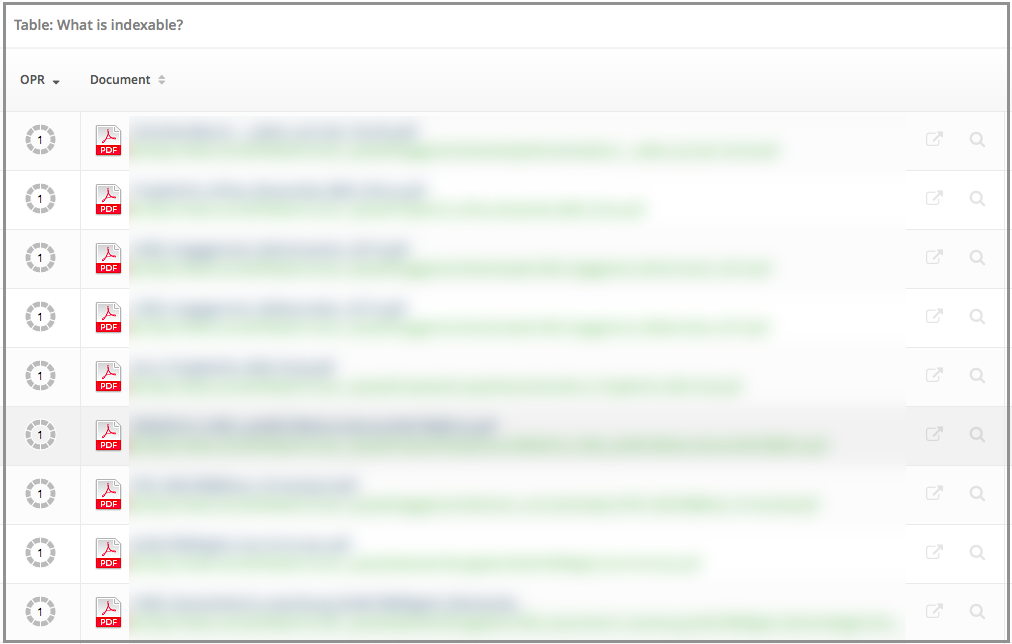
Рисунок 4: Список всех индексируемых PDF-файлов
Список всех PDF-файлов, которые уже есть в индексе Google, можно просмотреть с помощью поисковых операторов «file type: pdf» и «site: domain.tld»:
Рисунок 5: Список всех PDF-файлов, которые уже есть в индексе Google
Вариант 2:
Определите индексируемость PDF-файлов, которые имеют отношение к индексации
В некоторых случаях предоставление PDF-файлов для индекса Google может принести дополнительную пользу вашим пользователям. Это особенно полезно, если PDF-файлы содержат конкретную информацию, которая важна для пользователя, и пользователю не нужно взаимодействовать с веб-сайтом.
Хорошим примером являются планы сети общественного транспорта, такие как план мюнхенской сети метро. Все, что нужно пользователям - это быстро получить информацию, скачать PDF и сохранить ее на своих мобильных устройствах без взаимодействия с веб-сайтом.
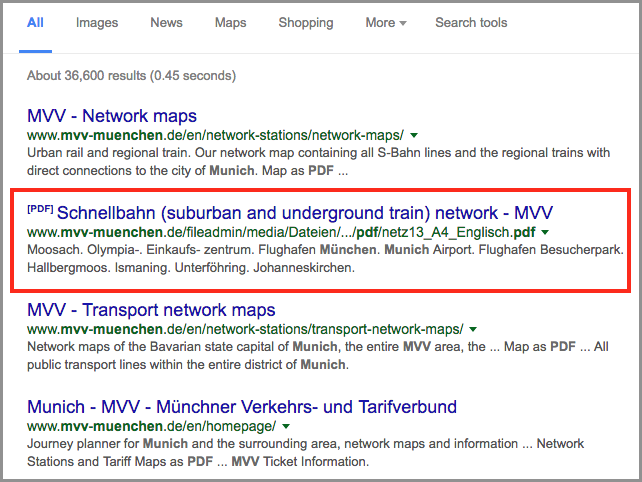
Рисунок 6: Пример PDF, который хорошо подходит в качестве целевой страницы в индексе поисковой системы
Рисунок 7: Сетевой план Мюнхена в формате PDF
Индексируемость документа является наиболее важной предпосылкой появления PDF в индексе поисковой системы.
Критерии индексируемости:
- Код статуса HTTP 200 OK
- Noindex не должен использоваться в качестве мета-роботов
- Если используется канонический тег, он не должен указывать на другой URL
Документ не будет проиндексирован, если один из этих критериев не будет соблюден.
OnPage.org Zoom позволяет легко идентифицировать неиндексируемые PDF-файлы. Просто перейдите в «Индексируемость» → «Что индексируемо» и выберите «PDF». Затем это позволяет вам просматривать список неиндексируемых PDF-файлов на графике, а также соответствующие причины (например, все PDF-файлы, имеющие метатег тега noindex).
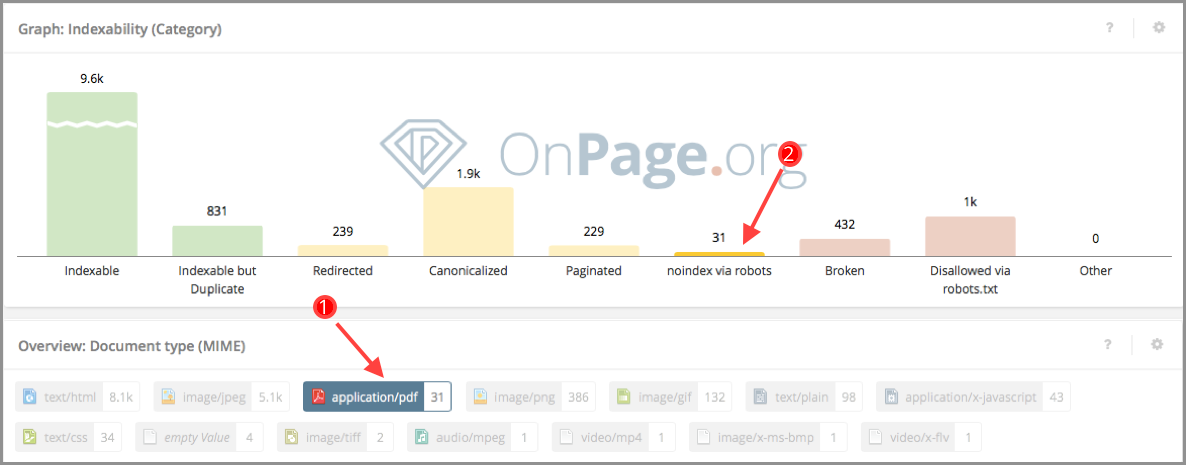
Рисунок 8: Определение неиндексируемых URL
Совет: индексируемые URL-адреса всегда должны содержать ссылку на соответствующую целевую страницу. Это позволяет пользователям быстро переходить на сайт.
Заключение
Подобно HTML-страницам, PDF-файлы также могут быть перечислены в результатах поиска. Однако не все документы PDF хорошо подходят в качестве целевых страниц. Поэтому вам следует подумать о той роли, которую PDF-файлы должны играть в вашей стратегии SEO, и найти способ максимально использовать их. PDF-файлы, которые не подходят в качестве целевых страниц, но содержат много входящей ссылки, должны содержать элемент x-robots в заголовке HTTP, указывающий на соответствующую целевую страницу. Что касается PDF-файлов, которые имеют отношение к индексации, вы должны убедиться, что они соответствуют всем критериям, которые необходимы для индексации.
Как Google обрабатывает PDF?Как Google обрабатывает PDF?
Просто перейдите в «Индексируемость» → «Что индексируемо?